This page contains a list of possible topics for the student presentations scheduled for 27 January to 31 January 2014. These are only suggestions, and other relevant topics are acceptable too.
Proper Scoring Functions
You want to know what the weather is going to be like tomorrow, so you buy a probability distribution p from a meteorologist. In order to reward good predictions, you tell the meteorologist that your payment will be contingent on what the weather actually turns out to be: If you observe weather x, you pay him p(x) euros for his efforts.
Unfortunately, this payment scheme gives the meteorologist an incentive to lie: His optimal strategy is to report a distribution that does not actually express his subjective beliefs about the weather tomorrow.
If you promise to pay the meteorologist log p(x) euro instead of p(x) euro, however, his optimal strategy is to report of his beliefs honestly. But the logarithm is not the only transformation of the distribution that rigs the game in this way. Any function that has this property is called a proper scoring function.
Some things you can look into under this heading are:
Unfortunately, this payment scheme gives the meteorologist an incentive to lie: His optimal strategy is to report a distribution that does not actually express his subjective beliefs about the weather tomorrow.
If you promise to pay the meteorologist log p(x) euro instead of p(x) euro, however, his optimal strategy is to report of his beliefs honestly. But the logarithm is not the only transformation of the distribution that rigs the game in this way. Any function that has this property is called a proper scoring function.
Some things you can look into under this heading are:
- Give examples of other proper scoring functions and prove that they are proper.
- Provide some criteria for recognizing a proper scoring function.
- Do any of the other scoring functions give rise to meaningful measures of uncertainty?
Proof of the Channel Coding Theorem
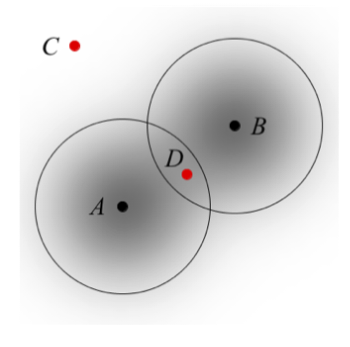
Somewhat surprisingly, Shannon’s channel coding theorem uses a proof based on random codes. That is, it shows that any bunch of sequences from the optimal input distribution to a channel is very likely to be a good code.
Like all statistical inference, however, choosing good codes involves the balancing of two kinds of errors: Having too many or too few candidates for an explanation of an observed effect. The core of Shannon's proof is the derivation of a bound on the probability of these two kinds of error. Good accounts of the proof are given in the textbooks by Cover and Thomas and McKay.
Things you can do under this heading:
Like all statistical inference, however, choosing good codes involves the balancing of two kinds of errors: Having too many or too few candidates for an explanation of an observed effect. The core of Shannon's proof is the derivation of a bound on the probability of these two kinds of error. Good accounts of the proof are given in the textbooks by Cover and Thomas and McKay.
Things you can do under this heading:
- Give a clear, intelligible, and detailed account of the proof.
- Illustrate by an example how the construction in the proof would work, for instance using the noisy typewriter example discussed in the two textbooks above.
- Explain the similarities and differences between the two types of decoding error and the notion of false negatives and false positives known from frequentist statistics.
Hamming Codes for the Binary Symmetric Channel

If you send messages through a binary channel with a fixed and symmetric probability of bit flips (i.e., 0 being received as 1 or vice versa), then your task as an encoder is essentially to choose codewords that are as far apart as possible in terms of bit flip distance.
A method for creating such codebooks was invented by Hamming in the 1940s. It turns out that his encoding method can be expressed as a certain kind of matrix multiplication, and the choice of encoding scheme for the binary symmetric channel thus corresponds to a choice of matrix. The reverse inference problem then similarly becomes a linear algebra problem.
Things you can do under this topic:
A method for creating such codebooks was invented by Hamming in the 1940s. It turns out that his encoding method can be expressed as a certain kind of matrix multiplication, and the choice of encoding scheme for the binary symmetric channel thus corresponds to a choice of matrix. The reverse inference problem then similarly becomes a linear algebra problem.
Things you can do under this topic:
- Read Hamming’s original paper and a more modern presentation of his ideas.
- Explain how the (7,4) Hamming code works.
- Explain the how Hamming codes can be represented as matrices.
- Find the error rate of a Hamming code and show it depends on the bit flip probability, the length of the code word, and the number of parity check bits.
Uniqueness of the Logarithmic Uncertainty Measure
In his 1948 paper, Shannon gave a small set of axioms that were sufficient to uniquely select entropy as a measure of uncertainty (up to the choice of logarithmic base). Other authors since him have used slightly different but equivalent sets of axioms, and many textbooks in information theory contain a version of this theorem.
Some things you can do under this topic are:
Some things you can do under this topic are:
- Choose a specific set of axioms and prove that the entropy is the only function fulfilling them.
- Compare different axiomatizations.
- Discuss which of the axioms that constitute the most substantial assumptions, and if they can be relaxed.
Dynamic Programming for Probabilistic Inference
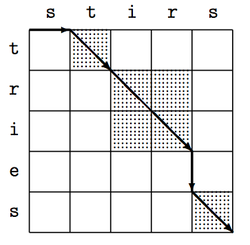
What’s the optimal way of inserting spaces into the string sevenseamensetouttosea? What is the smallest number of changes you have to make in order to turn the word glitch into the word slither? What’s the most probable syntactic analysis of a phrase like pretty little girl’s house?
All of these problems can be solved by a kind of systematic bottom-up recursion known as dynamic programming. Unlike ordinary recursion, the idea in dynamic programming is to start with small subproblems, save partial results as you go, and make sure that you never solve same subproblem twice.
This bottom-up approach to computational problems is immensely useful and has many important applications in probability theory.
Some things you can do under this heading:
All of these problems can be solved by a kind of systematic bottom-up recursion known as dynamic programming. Unlike ordinary recursion, the idea in dynamic programming is to start with small subproblems, save partial results as you go, and make sure that you never solve same subproblem twice.
This bottom-up approach to computational problems is immensely useful and has many important applications in probability theory.
Some things you can do under this heading:
- Take any recursive algorithm you have used in the past and check whether it can be solved by dynamic programming. If so, see how many function calls it would save you.
- Show how to solve the edit-distance problem (glitch–slither) using dynamic programming.
- Solve the space-insertion problem (sevenseamensetouttosea).
- Explain how the CYK parsing algorithm works and work through an explample.
- Devise an algorithm that can parse output from a echo machine, i.e., one that generates binary words and prints them twice before continuing (yielding output like 10.10.1101.1101, just without the periods).
Convolutional Codes, Hidden Markov Models, and the Viterbi Algorithm
Suppose an information source produces the messages 1, 0, 1 separated by one second, and that these messages must send them through a channel with a capacity of three bits per second.
One way to do this is to start with the all-zero codeword 000, and then serially replace the first signal bit with the first message, the second signal bit with the second message bit, and the third with the third. You would then transmit these these signals:
One way to do this is to start with the all-zero codeword 000, and then serially replace the first signal bit with the first message, the second signal bit with the second message bit, and the third with the third. You would then transmit these these signals:
- 100, 100, 101.
- 110, 100, 001.
This style of encoding (where the choice of a particular codeword depends on previous choices) is known as convolutional codes. The corresponding decoding procedure can be solved using an algorithm known as the Viterbi algorithm.
Things you can do:
Things you can do:
- Explain how the Viterbi algorithm works.
- Explain the parallelism between shortest path problems and the decoding problem.
- The Viterbi algorithm can also be used to assign part-of-speech tags (e.g. "noun") to unlabeled text. Explain how this works.
- Find out what the probability of error is with this type of encoding and decoding.
- Explain why the algorithm works in terms of inference on Bayesian networks.
The Entropy of a Context-Free Grammar
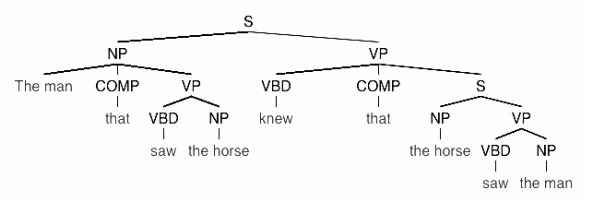
Suppose I write a down a specific context-free grammar and assign conditional probabilities to each rewrite rule:
S := NP VP (1.0)
NP := NP (0.8) | NP COMP VP (0.2)
VP := VBD NP (0.9) | VBD COMP S (0.1)
COMP := that (1.0)
VBD := saw (0.4) | knew (0.6)
NP := the man (0.7) | the horse (0.3)
How much uncertainty do I have about the sentence generation process that such a grammar defines? What’s the entropy of the grammar, considered as a tree-generation process?
A method for answering this question was proposed in 1967 by Ulf Grenander, who noticed that each rewrite rule defines a conditional entropy. The entropy of the whole process must thus satisfy a set of recurrence equations defined by the grammar. Such a set of equations can be solved using techniques from linear algebra.
There are a number of related issues you can focus on under this question:
A method for answering this question was proposed in 1967 by Ulf Grenander, who noticed that each rewrite rule defines a conditional entropy. The entropy of the whole process must thus satisfy a set of recurrence equations defined by the grammar. Such a set of equations can be solved using techniques from linear algebra.
There are a number of related issues you can focus on under this question:
- Expand and detail the idea sketched above
- Run the method on an example
- Get your hands on a treebank, construct a grammar from it, and compute its entropy
- Explain how this method can be extended to estimate the entropy of the ending of a sentence given the beginning (i.e., how uncertain are you about the conclusion of the sentence I saw the man that … ?)
Codebreaking for Traditional Cipher Systems
Information theory provides general insights about the security of various encryption schemes. However, cracking an "insecure" cipher often requires a lot of clever probabilistic inference, for instance in the form of sampling schemes like Gibbs sampling of the posterior distribution over encryption keys.
This topic is a practical challenge: I provide a number of texts, each of which are encrypted using a different type of encryption scheme. Your task will be to squeeze information out of these ciphers by any means you want, documenting the methods you used and the successes and failures they led to. It is absolutely not necessary that you crack all of the ciphers, or even try to do so.
The encrypted texts are all in English, and they were snipped quite randomly out of Project Gutenberg books. In some cases, they were transformed to uppercase letters only. In other cases, they were preserved in the original form.
The resulting ciphers are the following:
The Journal of Cryptology might be a good place to look for help on how to attack these problems. Kevin Knight has also written a number of papers on cryptography from an explicitly Bayesian viewpoint (e.g., this one).
This topic is a practical challenge: I provide a number of texts, each of which are encrypted using a different type of encryption scheme. Your task will be to squeeze information out of these ciphers by any means you want, documenting the methods you used and the successes and failures they led to. It is absolutely not necessary that you crack all of the ciphers, or even try to do so.
The encrypted texts are all in English, and they were snipped quite randomly out of Project Gutenberg books. In some cases, they were transformed to uppercase letters only. In other cases, they were preserved in the original form.
The resulting ciphers are the following:
- A substitution cipher.
- A permutation cipher.
- A running key cipher, here represented as the sum of two ASCII codes (e.g., A + Z = 65 + 90 = 155). Both the key and the encrypted text were converted to uppercase before encryption.
- An Enigma-style, periodic, polyalphabetic cipher.
- A cipher encrypted with both substitution and permutation.
- A Zodiac-style homophonic cipher encrypted by means of a Chinese restaurant process so that each letter can have several translations. The plaintext behind this cipher was converted to uppercase before encryption.
The Journal of Cryptology might be a good place to look for help on how to attack these problems. Kevin Knight has also written a number of papers on cryptography from an explicitly Bayesian viewpoint (e.g., this one).
The St. Petersburg Paradox

The St. Petersburg game is a hypothetical game which was hotly debated in the 18th century because it seemed to provide an example in which probability theory recommended irrational decisions. This spurred a number of mathematical and philosophical responses, most notably Daniel Bernoulli's 1738 paper on the topic.
The game itself runs as follows: In order to enter the game, you must pay a lump sum of c ducats. Once you have entered, a single ducat is put in a pot, and a coin is flipped. Every time the coin comes up heads, the prize in the pot is doubled; as soon as it comes up tails, you win all the money in the pot.
Some questions you can explore about this game are:
The St. Petersburg game and some of its extensions are also the subject of an elaborate exercise in ch. 6 of Cover and Thomas' textbook.
The game itself runs as follows: In order to enter the game, you must pay a lump sum of c ducats. Once you have entered, a single ducat is put in a pot, and a coin is flipped. Every time the coin comes up heads, the prize in the pot is doubled; as soon as it comes up tails, you win all the money in the pot.
Some questions you can explore about this game are:
- Give a mathematical argument in favor of entering the game however high the price c is.
- Give a counterargument supporting the 18th-century intuition that this is irrational.
- Discuss Daniel Bernoulli's resolution of the paradox and its relation to information theory.
- Read and evaluate other solutions that have been proposed in the literature.
- Suppose you did not pay a lump sum to enter the game, but instead paid a tax on your profits. Under what levels of taxation would it then be rational for you to enter the game?
- Suppose that instead of starting with 1 ducat in the pot and doubling the size of the pot with every coin flip, you started with 2 ducats and sqaured the size of the pot instead. What would be a fair taxation scheme for this "super St. Petersburg" game?
- What would be a fair taxation scheme if the game paid n ducats with a probability proportional to 1/n²?
- Discuss how the game is related to the Martingale gambling strategy of doubling your bet every time you lose.
- Explore the ways in which the St. Petersburg game is related to buying insurances and other types of risk-averse economic behavior.
The St. Petersburg game and some of its extensions are also the subject of an elaborate exercise in ch. 6 of Cover and Thomas' textbook.
Restricted Question/Answer Protocols and Their Uncertainty Measures
Suppose that I hide and object in one N buckets according to some distribution. You then try to determine as fast as possible where the object is by asking me a series of yes/no questions.
The entropy of my distribution is then a reasonable approximation of the average number of questions you will have to ask when using your optimal strategy, and the maximum entropy distribution is my optimal strategy. This is, however, only the case when the question-answer protocol allows you to ask arbitrary yes/no questions. Other protocols will correspond to different optimal strategies, and thus to different uncertainty measures.
The topic is related to the game-theoretical formulations of E. T Jaynes' maximum entropy principle, and you might want to take a look at some of the literature about that. Some more questions worth thinking about are:
A note of warning: The questions related to this topic can very quickly get very difficult, so this topic is mostly for the adventurous.
The entropy of my distribution is then a reasonable approximation of the average number of questions you will have to ask when using your optimal strategy, and the maximum entropy distribution is my optimal strategy. This is, however, only the case when the question-answer protocol allows you to ask arbitrary yes/no questions. Other protocols will correspond to different optimal strategies, and thus to different uncertainty measures.
The topic is related to the game-theoretical formulations of E. T Jaynes' maximum entropy principle, and you might want to take a look at some of the literature about that. Some more questions worth thinking about are:
- What kind of restrictions could reasonably be imposed on probability distributions accessible to the Hider?
- What happens if the Seeker can ask any question at all (not just yes/no questions)?
- What happens if the Seeker can only ask questions of the type "Is the object in bucket no. 17?"? (Notice that the game of Mastermind uses this protocol, but with a very particular kind of response from the Hider.)
- In the game "Guess Who?", the Seeker has to identify a person based on yes/no questions. The complexity associated with this task varies depending on the layout of the board, and some questions to think about are: For a specific layout what is the relevant uncertainty measure given that the Seeker can only ask questions of the form "Is F(x) the case?"? What if the Seeker can also use conjunctions and negations? How computationally difficult is it to compute the optimal strategy, in either of these versions, or in the unrestricted version?
- In one of the many games bearing the game Hide-and-Seek, the N buckets are arranged in a linear order. The Seeker can then guess by pointing to a particular bucket, and the Hider responds by revealing whether (1) the guess was correct, (2) the correct bucket is to left of the guess, or (3) the correct bucket is to the right. What does the uncertainty function and the maximum uncertainty distribution look like in this game for N = 3 and N = 4? Can you say anything general about the maximum uncertainty distribution for large N? (Richard Epstein briefly discusses this game at the end of ch. 9 of his 1977 book.)
A note of warning: The questions related to this topic can very quickly get very difficult, so this topic is mostly for the adventurous.
Stopping Rules and Wald's equality
A stopping rule is a rule for deciding when to stop doing something, based on a finite amount of past data — for instance, when to leave the casino based on your past gambling record, or when to stop a series of clinical trials based on the results so far. Wald's equality is a theorem which states that the average gain associated with a specific stopping rule is equal to the expected gain from each individual trial, times the expected time before you stop.
Some things you might want to do with this topic are:
A good place to start learning about this topic is Robert Gallager's MIT course on stochastic processes.
Some things you might want to do with this topic are:
- Give a clear and careful proof of Wald's equality.
- Discuss what the theorem entails for gambling. Is it bad news?
- Discuss the implications of Wald's equality for statistics.
- Consider the gambling strategy "Stop when you're ahead": Before you enter the casino, you decide to leave once you have reached a certain level of capital c. What is the probability that you will ever leave the casino if you use this stopping rule?
- Think about the connection between stopping rules and Turing machines with infinite input tapes: A binary input tape can be seen as path through a binary tree, and a Turing machine can be seen as a deterministic rule for deciding whether you should stop or continue when you reach a particular node.
- Consider the relation to finite stopping problems like the secretary problem.
A good place to start learning about this topic is Robert Gallager's MIT course on stochastic processes.
The Solomonoff Prior (Universal Probability)
Described in the fifth class.
Biological Evolution and the Second Law of Thermodynamics
Briefly hinted at in the third class.
Stirling's Approximation and the Binomial Distribution
As hinted at in the fifth class.
